Title here
Summary here
A brief introduction to llmaz and the features published in the first minor release v0.1.0.
With the GPT series models shocking the world, a new era of AI innovation has begun. Besides the model training, because of the large model size and high computational cost, the inference process is also a challenge, not only the cost, but also the performance and efficiency. So when we look back to the late of 2023, we see lots of communities are building the inference engines, like the vLLM, TGI, LMDeploy and more others less well-known. But there still lacks a platform to provide an unified interface to serve LLM workloads in cloud and it should work smoothly with these inference engines. That’s the initial idea of llmaz. However, we didn’t start the work until middle of 2024 due to some unavoidable commitments. Anyway, today we are proud to announce the first minor release v0.1.0 of llmaz.
💙 To make sure you will not leave with disappointments, we don’t have a lot of fancy features for v0.1.0, we just did a lot of dirty work to make sure it’s a workable solution, but we promise you, we will bring more exciting features in the near future.
First of all, let’s take a look at the architecture of llmaz:
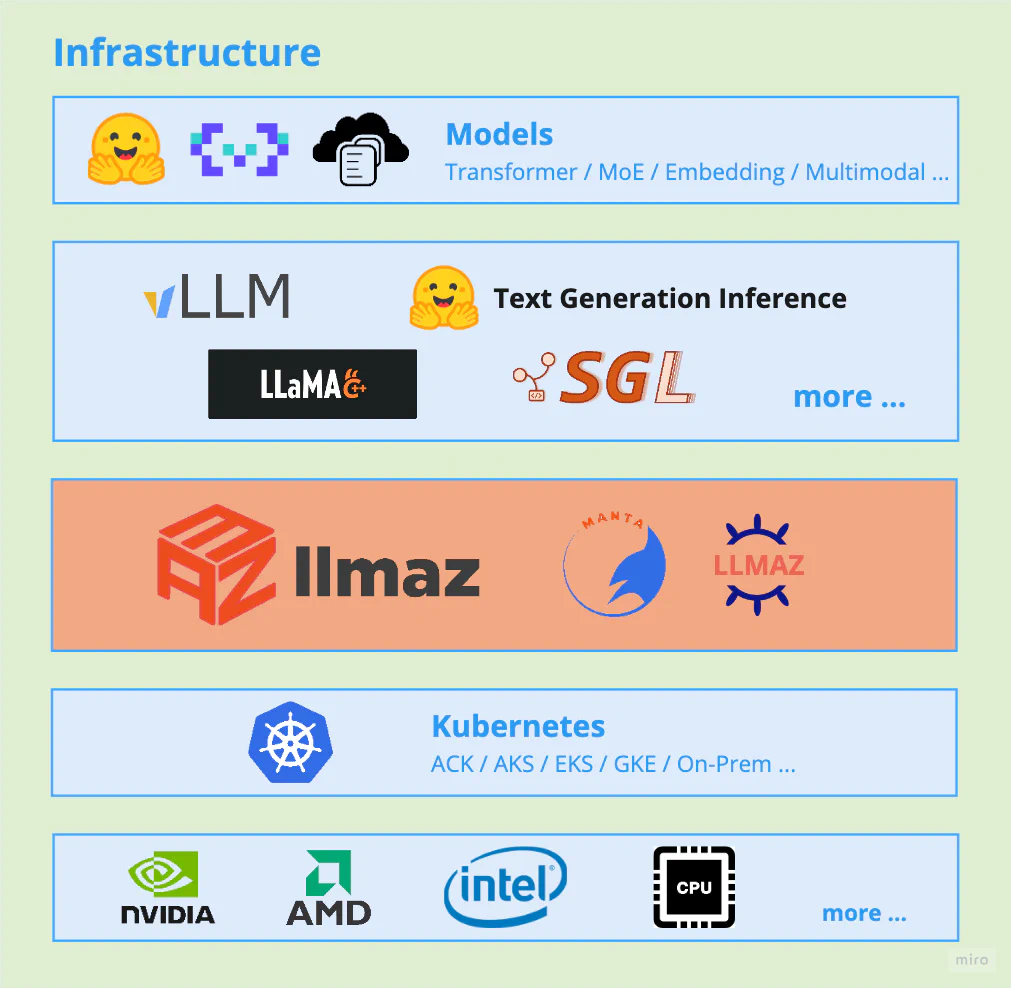
Basically, llmaz works as a platform on top of Kubernetes and provides an unified interface for various kinds of inference engines, it has four CRDs as defined:
With the abstraction of these CRDs, llmaz provides a simple way to deploy and manage the inference workloads, offering features like:
With llmaz v0.1.0, all these features are available. Next, I’ll show you how to use llmaz.
First, you need to install the llmaz with helm charts, be note that the helm chart version is different with the llmaz version, 0.0.6 is exactly the version of llmaz v0.1.0.
helm repo add inftyai https://inftyai.github.io/llmaz
helm repo update
helm install llmaz inftyai/llmaz --namespace llmaz-system --create-namespace --version 0.0.6You can find more installation guides here like installing from source code.
Here’s the simplest way to deploy a model with llmaz.
apiVersion: llmaz.io/v1alpha1
kind: OpenModel
metadata:
name: opt-125m
spec:
familyName: opt
source:
modelHub:
modelID: facebook/opt-125m
inferenceConfig:
flavors:
- name: default
requests:
nvidia.com/gpu: 1apiVersion: inference.llmaz.io/v1alpha1
kind: Playground
metadata:
name: opt-125m
spec:
replicas: 1
modelClaim:
modelName: opt-125m
# To use elasticConfig, you need to add scaleTriggers to backendRuntime,
# if not, comment the elasticConfig here.
elasticConfig:
minReplicas: 1
maxReplicas: 3That’s it! llmaz will launch a opt-125m service with the replicas ranging from 1 to 3. The service is served by vLLM by default.
We believe that the complexity of the system should be hidden from the users, we have two main roles in our system, the user, and the platform runner.
The user, who wants to deploy a LLM model should not know too much details of the Kubernetes (although llmaz is also deployed on Kubernetes), the only thing they need to do is to provide the model name, and llmaz should take care of the rest.
That’s the reason why we have the Playground, it’s a facade to the inference workload with model name, replicas configurations, we shift the complexity to the BackendRuntime instead. If you take a look at the vLLM BackendRuntime, the configuration is really long.
apiVersion: inference.llmaz.io/v1alpha1
kind: BackendRuntime
metadata:
labels:
app.kubernetes.io/name: backendruntime
app.kubernetes.io/part-of: llmaz
app.kubernetes.io/created-by: llmaz
name: vllm
spec:
commands:
- python3
- -m
- vllm.entrypoints.openai.api_server
multiHostCommands:
leader:
- sh
- -c
- |
ray start --head --disable-usage-stats --include-dashboard false
i=0
while true; do
active_nodes=`python3 -c 'import ray; ray.init(); print(sum(node["Alive"] for node in ray.nodes()))'`
if [ $active_nodes -eq $(LWS_GROUP_SIZE) ]; then
echo "All ray workers are active and the ray cluster is initialized successfully."
break
fi
if [ $i -eq 60 ]; then
echo "Initialization failed. Exiting..."
exit 1
fi
echo "Wait for $active_nodes/$(LWS_GROUP_SIZE) workers to be active."
i=$((i+1))
sleep 5s;
done
python3 -m vllm.entrypoints.openai.api_server
worker:
- sh
- -c
- |
i=0
while true; do
ray start --address=$(LWS_LEADER_ADDRESS):6379 --block
if [ $? -eq 0 ]; then
echo "Worker: Ray runtime started with head address $(LWS_LEADER_ADDRESS):6379"
break
fi
if [ $i -eq 60 ]; then
echo "Initialization failed. Exiting..."
exit 1
fi
echo "Waiting until the ray worker is active..."
sleep 5s;
done
image: vllm/vllm-openai
version: v0.6.0
# Do not edit the preset argument name unless you know what you're doing.
# Free to add more arguments with your requirements.
args:
- name: default
flags:
- --model
- "{{ .ModelPath }}"
- --served-model-name
- "{{ .ModelName }}"
- --host
- "0.0.0.0"
- --port
- "8080"
- name: speculative-decoding
flags:
- --model
- "{{ .ModelPath }}"
- --served-model-name
- "{{ .ModelName }}"
- --speculative_model
- "{{ .DraftModelPath }}"
- --host
- "0.0.0.0"
- --port
- "8080"
- --num_speculative_tokens
- "5"
- -tp
- "1"
- name: model-parallelism
flags:
- --model
- "{{ .ModelPath }}"
- --served-model-name
- "{{ .ModelName }}"
- --host
- "0.0.0.0"
- --port
- "8080"
- --tensor-parallel-size
- "{{ .TP }}"
- --pipeline-parallel-size
- "{{ .PP }}"
resources:
requests:
cpu: 4
memory: 8Gi
limits:
cpu: 4
memory: 8Gi
startupProbe:
periodSeconds: 10
failureThreshold: 30
httpGet:
path: /health
port: 8080
livenessProbe:
initialDelaySeconds: 15
periodSeconds: 10
failureThreshold: 3
httpGet:
path: /health
port: 8080
readinessProbe:
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3
httpGet:
path: /health
port: 8080Basically, the BackendRuntime configures the boot commands, the resource requirements, the probes, all the stuff related to the inference engine, also part of the workload’s Pod yaml. We believe it’s workable for several reasons:
Regarding to the OpenModel, we think model should be the first citizen in the cloud management, who has lots of properties, like the source address, the inference configurations, the metadata, etc.. We believe it’s a good practice to separate the model from the inference workload, and we can reuse the model in different workloads.
For the long-term consideration, we may support model fine-tuning and model training in the future, so the OpenModel for serving is a good start.
And we would like to highlight the inference configs of OpenModel, particularly the inference flavors, in cloud, we claim a Nvidia GPU with requests like nvidia.com/gpu: 1, this is not good enough because GPU chips have different series, like P4, T4, L40S, A100, H100, H200, they have different memory bandwidth and compute capability, even the same chip series may have different types like the A100 has the 40GB and 80GB, and we can’t tolerate to use low-end GPUs like the T4 to serve the SOFT models like llama3 405B or DeepSeek V3, so we need to specify the inference requirements in the model.
Here, I demonstrate how to deploy the llama3 405B with flavors configured, it will first try to scheduler the Pods to the nodes with the label gpu.a100-80gb: true, if not, fallback to the nodes with label gpu.h100: true (this requires to install our new written scheduler plugin, we’ll reveal it in the following posts).
apiVersion: llmaz.io/v1alpha1
kind: OpenModel
metadata:
name: llama3-405b-instruct
spec:
familyName: llama3
source:
modelHub:
modelID: meta-llama/Llama-3.1-405B
inferenceConfig:
flavors:
- name: a100-80gb
requests:
nvidia.com/gpu: 8 # single node request
params:
TP: "8" # 8 GPUs per node
PP: "2" # 2 nodes
nodeSelector:
gpu.a100-80gb: true
- name: h100
requests:
nvidia.com/gpu: 8 # single node request
params:
TP: "8"
PP: "2"
nodeSelector:
gpu.h100: true
---
apiVersion: inference.llmaz.io/v1alpha1
kind: Playground
metadata:
name: llama3-405b-instruct
spec:
replicas: 1
modelClaim:
modelName: llama3-405b-instruct
backendRuntimeConfig:
resources:
requests:
cpu: 4
memory: 8Gi
limits:
cpu: 4
memory: 16GiThen llmaz will launch a multi-host inference service with 2 nodes, each node has 8 GPUs of A100 80GB/H100, the tensor parallelism is 8, the pipeline parallelism is 2, running by vLLM.
So this is our first minor release, as we mentioned, we did a lot of dirty work to make it easy to use, but we also left some unfinished work, especially the model distribution, this is a really pain-point, we have some on-going work but not ready for v0.1.0.
So here’s the roadmap for v0.2.0:
And it’s also great to have features like scale-to-zero serving, python SDK for code integration.
We would like to thank all the contributors who helped us to make this release happen, it’s really happy and grateful to have you all as a new open-source project.
And we are looking forward to user feedbacks as well, if you’re interested with llmaz, feel free to have a try and if you have any problems or suggestions, don’t hesitate to contact us, open an issue or PR on our GitHub repository is also welcomed.
Last but not least, don’t forget to 🌟️ our repository if you like it, it’s a great encouragement for us.